.bashrc를 활용한 환경 변수 영구 등록
리눅스(Ubuntu)에는 사용자가 로그인할 때마다 자동으로 읽어 들이는 환경 설정 파일이 있다. 바로 홈 디렉토리에 숨어있는 .bashrc (또는 .profile) 파일이다. 여기에 비밀번호를 적어두면 평생 지워지지 않는다.
nano ~/.bashrc
- 환경 변수 추가하기
파일의 맨 아랫줄 빈 공간에 우리가 사용할 가상의 API 키를 적어주자
export MY_API_KEY="my_secret_aws_key_999"
- 변경 사항 즉시 적용하기!! (중요하다~) 파일을 수정했다고 바로 적용되는 것이 아닙니다. 컴퓨터를 껐다 켜거나, 리눅스에게 “설정 파일 다시 읽어!”라고 명령해야 한다.
source ~/.bashrc
이제 터미널을 껐다 켜도 echo $MY_API_KEY를 치면 비밀번호가 잘 출력된다.
파이썬에서 변수 불러오기
이제 파이썬에서 이 키를 가져다 써보자. 복잡한 외부 라이브러리나 무거운 설정 클래스를 짤 필요 없이, 파이썬 내장 라이브러리인 os를 사용하는 것이 좋다.
cd ~/server_prac
nano api_test.py
- os.getenv를 사용하여 운영체제에 숨겨둔 키를 안전하게 가져온다
import os
api_key = os.getenv('MY_API_KEY')
if api_key:
print(f"successfully loaded api key!: {api_key}")
else:
print("error!")
쉘 스크립트로 파일 압축 백업하기
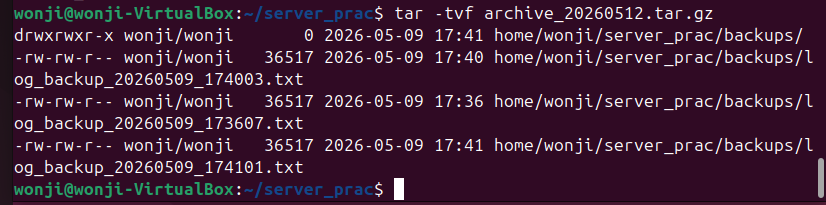
이번엔 지정된 폴더의 파일들을 하나로 묶어서 꽉 압축(zip)해 버리는 스크립트를 짜보자. 리눅스에서는 주로 tar 명령어를 쓴다.
- 압축 스크립트 작성
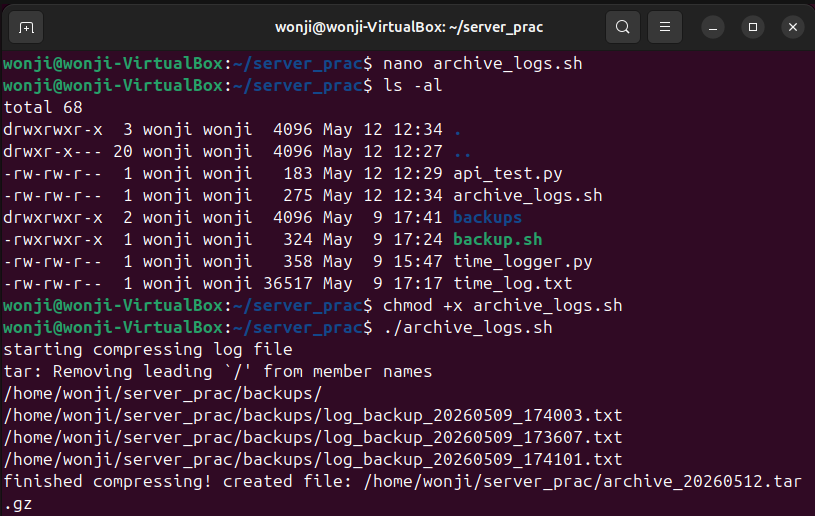
nano archive_logs.sh
- bash 코드 작성
- tar 명령어로 폴더 전체를 압축
- -c: 새로 만들기, -z: gzip 압축, -v: 진행상황 보이기, -f: 파일명 지정
#!/bin/bash
TODAY=$(date +%Y%m%d)
SOURCE_DIR="/home/wonji/server_prac/backups"
TARGET_FILE="/home/wonji/server_prac/archive_${TODAY}.tar.gz"
echo "로그 파일 압축을 시작"
tar -czvf $TARGET_FILE $SOURCE_DIR
echo "압축 완료! 생성된 파일: $TARGET_FILE"
- 실행 권한 부여 및 테스트
chmod +x archive_logs.sh
./archive_logs.sh